Preliminary application of a cervical vertebra segmentation method based on Transformer and diffusion model for lateral cephalometric radiographs in orthodontic clinical practice
LIU Yang,1, WU Mengyi,2, HU Yao2, QI Kun3, WANG Yubin2, ZHAO Yue,2, SONG Jinlin,1
1.Department of Orthodontics, Stomatological Hospital of Chongqing Medical University, Chongqing 401147, China
2.School of Communication and Information Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
3.Department of Orthodontics, Stomatological Hospital of Xi'an Jiaotong University, Xi'an 710004, China
目的·针对错畸形生长发育高峰期骨骼形态变化复杂、难以精准评估的临床难点,利用扩散模型与Transformer深度学习算法构建颈椎图像分割模型并评估其分割性能。方法·使用基于Transformer与扩散模型相结合的方法对185例正畸患者(44例来自重庆医科大学附属口腔医院,141例来自西安交通大学口腔医院)的头颅侧位片进行精准的颈椎分割。首先对图像进行预处理,裁剪出感兴趣的颈椎骨区域,随机将所有数据划分为训练集(79.6%)和测试集(20.4%)。利用U-Net构成的扩散模型和条件模型进行特征提取,引入Transformer模块学习噪声和语义特征之间的相互作用。将多尺度图像进行融合,以增强低对比度图像中的细微结构和边界纹理特征。将该方法与U-Net和SOLOv2方法进行比较,通过Dice相似系数(Dice similarity coefficient,DSC)、交并比(intersection over union,IoU)2项指标定量比较颈椎图像分割性能。通过医师的人工标注结果和模型可视化结果对分割性能进行定性评估。结果·基于Transformer的扩散模型颈椎图像分割方法的DSC和IoU评分分别达到93.3%和87.5%,明显优于U-Net和SOLOv2方法(在DSC上分别领先3.0%和4.1%,在IoU上分别领先5.2%和7.1%)。尽管单张图像的处理时间较长,但分割精度显著提升。相较于U-Net和SOLOv2,基于Transformer的扩散模型颈椎图像分割方法在处理复杂、低对比度和边界模糊的图像时表现出更高的稳定性和鲁棒性,能够精准分割出颈椎骨的清晰边界和完整结构。结论·基于Transformer的扩散模型颈椎图像分割网络能够增强颈椎图像中的边缘和纹理特征,更容易识别不同椎骨的边界,从而获得自动、准确、稳健的颈椎分割结果,可辅助颈椎骨成熟度分析。
关键词:扩散模型
;
颈椎分割
;
深度学习
;
头颅侧位片
Abstract
Objective ·To construct a cervical vertebra image segmentation model by using a diffusion model with the Transformer deep learning algorithm, and evaluate its segmentation performance, to address the clinical challenge of accurately assessing complex changes in skeletal morphology during the growth and developmental peaks of malocclusion. Methods ·Accurate cervical vertebra segmentation was performed on cephalometric radiographs from 185 orthodontic patients (44 cases from the Stomatological Hospital of Chongqing Medical University and 141 cases from the Stomatological Hospital of Xi'an Jiaotong University) by using a method combining Transformer and diffusion models. First, the images were preprocessed to crop out the cervical vertebra region of interest, and all data were randomly divided into a training set (79.6%) and a test set (20.4%). The diffusion model and a conditional model based on U-Net were utilized for feature extraction, with a Transformer module introduced to learn the interaction between noise and semantic features. Multi-scale images were fused to enhance fine structure and boundary texture features in low-contrast images. The proposed method was compared with U-Net and SOLOv2 methods. The segmentation performance was quantitatively evaluated by two metrics, Dice Similarity Coefficient (DSC) and Intersection over Union (IoU), and also qualitatively assessed through physicians' manual annotations and model visualization results. Results ·The cervical vertebra segmentation method based on Transformer and diffusion models achieved DSC and IoU scores of 93.3% and 87.5%, respectively, significantly outperforming the U-Net and SOLOv2 methods (with improvements of 3.0% and 4.1% in DSC, and 5.2% and 7.1% in loU, respectively). Despite the longer processing time for a single image, segmentation accuracy was significantly improved. Compared with U-Net and SOLOv2, the proposed method also showed higher stability and robustness in processing complex, low-contrast and blurred-boundary images, and was able to accurately segment the cervical vertebrae with clear boundaries and complete structures. Conclusion ·The Transformer-based diffusion model for cervical vertebra segmentation can enhance the edge and texture features in cervical vertebra images and recognize the boundaries of different vertebrae more easily. Thus, automatic, accurate, and robust cervical vertebra segmentation results are achieved, which can assist in cervical vertebral maturation analysis.
Keywords:diffusion model
;
cervical vertebra segmentation
;
deep learning
;
lateral cephalometric radiograph
LIU Yang, WU Mengyi, HU Yao, QI Kun, WANG Yubin, ZHAO Yue, SONG Jinlin. Preliminary application of a cervical vertebra segmentation method based on Transformer and diffusion model for lateral cephalometric radiographs in orthodontic clinical practice. Journal of Shanghai Jiao Tong University (Medical Science)[J], 2024, 44(12): 1579-1586 doi:10.3969/j.issn.1674-8115.2024.12.011
受到基于扩散模型的医学图像分割MedSegDiff-V2[21]网络启发,本文提出了一种基于Transformer与扩散模型相结合的颈椎分割方法,旨在提高低质量图像颈椎分割的准确性,辅助临床医师预测青少年生长发育情况以确定最佳正畸治疗时机。本研究利用扩散模型与Transformer深度学习算法,针对错畸形生长发育高峰期难以把控的临床难点,构建颈椎图像分割模型并评估其分割性能。本方法在191个用于颈椎分割的数据集上进行了训练和评估,并与目前图像分割的SOTA(state of the art)方法(U-Net[22]和SOLOv2[23]方法)进行比较,通过Dice相似系数(Dice similarity coefficient,DSC)、交并比(intersection over union,IoU)2个指标对分割性能进行定量评估。
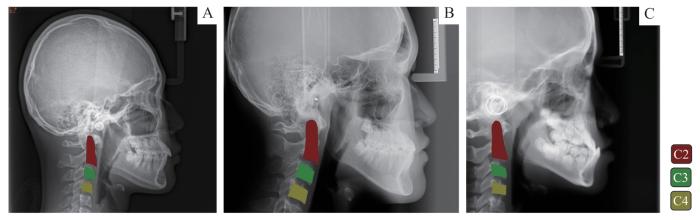
Note: Three samples, designated from A to C, were randomly selected from 191 cases of manually annotated lateral cephalometric radiographs by radiologists. In these samples, C2, C3, and C4 corresponded to the second, third, and fourth vertebrae of the cervical spines, respectively.
Fig 1
Lateral cephalometric radiographs and manual annotations
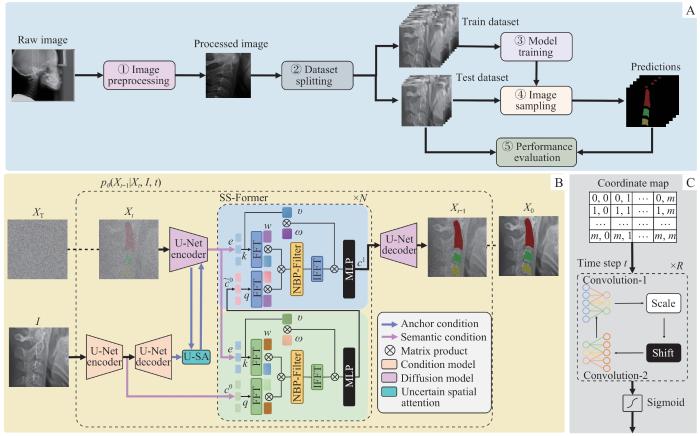
Note: A. Overall architecture of the MedSegDiff-V2 network. The network took raw cranial lateral slice data as input, and proceeded to obtain results pertaining to the segmentation of the cervical vertebrae. It was achieved through a five-step process. ①Image preprocessing. The region of interest (ROI) was cropped and resized to 256×256 pixels. ②Dataset splitting. The 191 images were divided into two sets: 152 for training and 39 for testing. ③Model training. The MedSegDiff-V2 model was trained using the training dataset. ④Image sampling. Images from the test dataset were sampled using the trained diffusion. ⑤Performance evaluation. The DSC and IoU formulas were used to calculate the corresponding metrics from the ground truth masks and model predictions of the test dataset. B. MedSegDiff-V2 architecture. A Transformer-based diffusion network for image segmentation. FFT—Fast Fourier Transform; IFFT—reverse operation of the FFT; MLP—multi-layer perceptron; U-SA—uncertain spatial attention; NBP-Filter—neural band-pass filter. C. Neural band-pass filter.
Fig 2
A Transformer-based cervical vertebra segmentation network for diffusion model
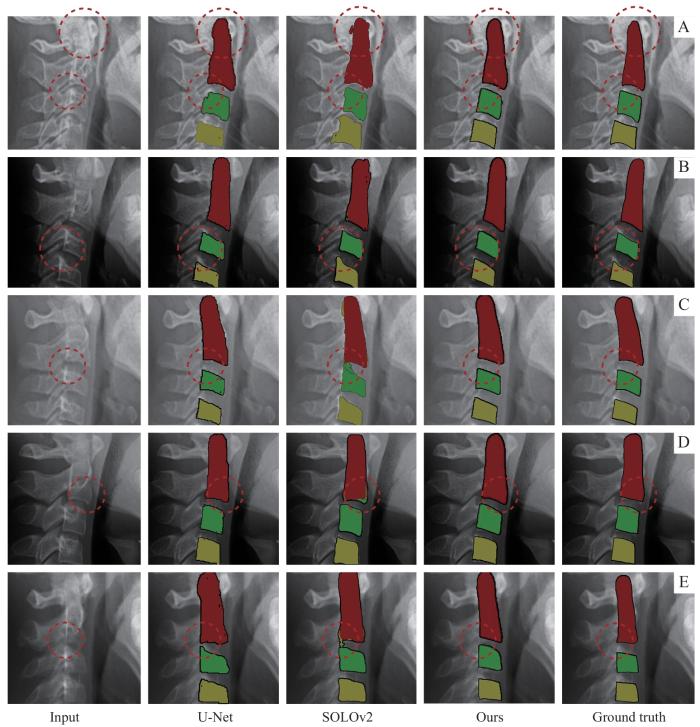
Note: Five samples, designated from A to E, were randomly selected from the test set data of cervical vertebra segmentation images. The cervical vertebra segmentation method based on the Transformer and diffusion model was compared with the original input image, two additional methods (U-Net and SOLOv2), and the ground truth. The regions delineated by the dashed circles represent the areas where the segmentation results of the various methods differ from the ground truth.
Fig 3
Visualization of segmentation results obtained by different methods and the respective manual ground-truth annotations for five examples
尽管基于Transformer的扩散模型在单张图像上的处理时间慢于U-Net和SOLOv2,但其分割精度提升显著,更适用于对精度要求较高的临床应用。为了克服扩散模型训练所需的计算量较大和推理速度较慢的缺点,现有的一些工作也在尝试从多种角度出发降低扩散模型的复杂度以提高扩散模型的效率。例如,SONG等[25]将扩散模型中马尔可夫过程替换为更高效的非马尔可夫过程,能够在显著减少采样步骤的情况下,保证生成高质量的样本,将采样速度提升10~50倍;但其性能仍然依赖于硬件条件,对于大规模高分辨率图像生成,计算成本仍然不容忽视。DUAN等[26]设计了一个更优质的最优线性子空间搜索算法(optimal linear subspace search,OLSS)以加速扩散进程,其能够在很少的步骤内生成高质量图像,通过使用潜在扩散模型并应用OLSS,只需数秒钟就能生成1张高质量的图像。尽管OLSS在推理阶段表现优越,但其实现需要复杂的训练过程,包括线性子空间扩展和路径优化算法,使得模型的开发和维护成本增加。未来,仍需研究更高效的扩散模型用于医学图像分割,以辅助医师进行临床诊断、治疗方案确定和手术规划。
LIU Yang, WU Mengyi, and HU Yao were responsible for writing and revising the paper. LIU Yang, QI Kun and SONG Jinlin were responsible for data collection and analysis, and provided guidance related to orthodontic and cervical bone age staging assessment. HU Yao and WANG Yubin were responsible for the experimental design and running of the cervical spine segmentation model. ZHAO Yue was responsible for the paper revision and model architecture design guidance. All the authors have read the last version of paper and consented for submission.
利益冲突声明
所有作者声明不存在利益冲突。
COMPETING INTERESTS
All authors disclose no relevant conflict of interests.
LI H R, LI H Z, YUAN L J, et al. The psc-CVM assessment system: a three-stage type system for CVM assessment based on deep learning[J]. BMC Oral Health, 2023, 23(1): 557.
ALKHAL H A, WONG R W K, RABIE A B. Correlation between chronological age, cervical vertebral maturation and Fishman's skeletal maturity indicators in southern Chinese[J]. Angle Orthod, 2008, 78(4): 591-596.
GANDINI P, MANCINI M, ANDREANI F. A comparison of hand-wrist bone and cervical vertebral analyses in measuring skeletal maturation[J]. Angle Orthod, 2006, 76(6): 984-989.
BACCETTI T, FRANCHI L, JR MCNAMARA J A. An improved version of the cervical vertebral maturation (CVM) method for the assessment of mandibular growth[J]. Angle Orthod, 2002, 72(4): 316-323.
ASLAN M S, ALI A, RARA H, et al. An automated vertebra identification and segmentation in CT images[C]//2010 IEEE International Conference on Image Processing. Hong Kong, China: IEEE, 2010: 233-236.
YAO J H, BURNS J E, FORSBERG D, et al. A multi-center milestone study of clinical vertebral CT segmentation[J]. Comput Med Imaging Graph, 2016, 49: 16-28.
SHIM J H, KIM W S, KIM K G, et al. Evaluation of U-Net models in automated cervical spine and cranial bone segmentation using X-ray images for traumatic atlanto-occipital dislocation diagnosis[J]. Sci Rep, 2022, 12(1): 21438.
ZHANG F, ZHENG L Y, CHEN Y R, et al. Fully automatic cervical vertebrae segmentation via enhanced U2-Net[C]//2023 IEEE International Conference on Image Processing.Kuala Lumpur, Malaysia: IEEE, 2023: 2900-2904.
ZHANG L, WANG H. A novel segmentation method for cervical vertebrae based on PointNet++ and converge segmentation[J]. Comput Methods Programs Biomed, 2021, 200: 105798.
PAN E Y, ZHONG Y, LI P. Semi-supervised cervical spine MRI segmentation model in federated heterogeneous data[J]. Computer Engineering, 2024, 50(9): 367-376.
ZHU Y F, ZHAO K, GUO L, et al. Automatic segmentation of cervical spine structures on MRI images based on deep learning: a preliminary study[J]. Radiology Practice, 2021, 36(12): 1558-1562.
LI Q, HUANGFU Y B, LI J Y, et al. UConvTrans: a dual-flow cardiac image segmentation network by global and local information integration[J]. Journal of Shanghai Jiao Tong University, 2023, 57(5): 570-581.
ZHANG J N, SU Q X, WANG C, et al. A domain adaptive semantic segmentation network based on improved transformation network[J]. Journal of Shanghai Jiao Tong University, 2021, 55(9): 1158-1168.
LÜ C F, YAN Y J, LIN L, et al. Design of mandibular angle osteotomy plane based on point cloud semantic segmentation algorithm[J]. Journal of Shanghai Jiao Tong University, 2022, 56(11): 1509-1517.
DONG Z W, YUAN G J, HUA Z, et al. Diffusion model-based text-guided enhancement network for medical image segmentation[J]. Expert Syst Appl, 2024, 249: 123549.
LI G J, JIN D H, ZHENG Y J, et al. A generic plug & play diffusion-based denosing module for medical image segmentation[J]. Neural Netw, 2024, 172: 106096.
GUO X T, YANG Y W, YE C F, et al. Accelerating diffusion models via pre-segmentation diffusion sampling for medical image segmentation[C]//2023 IEEE 20th International Symposium on Biomedical Imaging. Cartagena, Colombia: IEEE, 2023: 1-5.
WU J D, JI W, FU H Z, et al. MedSegDiff-V2: diffusion based medical image segmentation with Transformer[EB/OL]. (2023-12-24) [2024-06-19]. http://arxiv.org/abs/2301.11798.
WANG X, ZHANG R, KONG T, et al. SOLOv2: dynamic and fast instance segmentation[C]//Advances in Neural Information Processing System 33 (NeurIPS 2020).Vancouver, Canada: NeurIPS, 2020: 17721-17732.
DUAN Z J, WANG C Y, CHEN C, et al. Optimal linear subspace search: learning to construct fast and high-quality schedulers for diffusion models[EB/OL].(2023-08-11) [2024-06-19].http://arxiv.org/abs/2305.14677.
... 受到基于扩散模型的医学图像分割MedSegDiff-V2[21]网络启发,本文提出了一种基于Transformer与扩散模型相结合的颈椎分割方法,旨在提高低质量图像颈椎分割的准确性,辅助临床医师预测青少年生长发育情况以确定最佳正畸治疗时机.本研究利用扩散模型与Transformer深度学习算法,针对错畸形生长发育高峰期难以把控的临床难点,构建颈椎图像分割模型并评估其分割性能.本方法在191个用于颈椎分割的数据集上进行了训练和评估,并与目前图像分割的SOTA(state of the art)方法(U-Net[22]和SOLOv2[23]方法)进行比较,通过Dice相似系数(Dice similarity coefficient,DSC)、交并比(intersection over union,IoU)2个指标对分割性能进行定量评估. ...
1
... 受到基于扩散模型的医学图像分割MedSegDiff-V2[21]网络启发,本文提出了一种基于Transformer与扩散模型相结合的颈椎分割方法,旨在提高低质量图像颈椎分割的准确性,辅助临床医师预测青少年生长发育情况以确定最佳正畸治疗时机.本研究利用扩散模型与Transformer深度学习算法,针对错畸形生长发育高峰期难以把控的临床难点,构建颈椎图像分割模型并评估其分割性能.本方法在191个用于颈椎分割的数据集上进行了训练和评估,并与目前图像分割的SOTA(state of the art)方法(U-Net[22]和SOLOv2[23]方法)进行比较,通过Dice相似系数(Dice similarity coefficient,DSC)、交并比(intersection over union,IoU)2个指标对分割性能进行定量评估. ...
1
... 受到基于扩散模型的医学图像分割MedSegDiff-V2[21]网络启发,本文提出了一种基于Transformer与扩散模型相结合的颈椎分割方法,旨在提高低质量图像颈椎分割的准确性,辅助临床医师预测青少年生长发育情况以确定最佳正畸治疗时机.本研究利用扩散模型与Transformer深度学习算法,针对错畸形生长发育高峰期难以把控的临床难点,构建颈椎图像分割模型并评估其分割性能.本方法在191个用于颈椎分割的数据集上进行了训练和评估,并与目前图像分割的SOTA(state of the art)方法(U-Net[22]和SOLOv2[23]方法)进行比较,通过Dice相似系数(Dice similarity coefficient,DSC)、交并比(intersection over union,IoU)2个指标对分割性能进行定量评估. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}